Type Merging
Type merging allows partial definitions of a type to exist in any subschema, all of which are merged into one unified type in the gateway schema. When querying for a merged type, the gateway smartly delegates portions of a request to each relevant subschema in dependency order and then combines all results for the final return.
Type merging is now the preferred method of including GraphQL types across subschemas, replacing the need for schema extensions (though does not preclude their use). To migrate from schema extensions, simply enable type merging and then start replacing extensions one by one with merges.
Basic Example
Type merging allows each subschema to provide subsets of a type that it has data for. For example:
import { makeExecutableSchema } from '@graphql-tools/schema'
import { addMocksToSchema } from '@graphql-tools/mock'
let postsSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
type Post {
id: ID!
message: String!
author: User!
}
type User {
id: ID!
posts: [Post]!
}
type Query {
postById(id: ID!): Post
postUserById(id: ID!): User
}
`
})
let usersSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
type User {
id: ID!
email: String!
}
type Query {
userById(id: ID!): User
}
`
})
// just mock the schemas for now to make them return dummy data
postsSchema = addMocksToSchema({ schema: postsSchema })
usersSchema = addMocksToSchema({ schema: usersSchema })Note that both services define a different User type. While the users service manages information about user accounts, the posts service simply provides posts associated with a user ID. Now we just have to configure the User type to be merged. Type merging requires a query from each subschema to provide its version of a merged type:
import { stitchSchemas } from '@graphql-tools/stitch'
const gatewaySchema = stitchSchemas({
subschemas: [
{
schema: postsSchema,
merge: {
User: {
fieldName: 'postUserById',
selectionSet: '{ id }',
args: originalObject => ({ id: originalObject.id })
}
}
},
{
schema: usersSchema,
merge: {
User: {
fieldName: 'userById',
selectionSet: '{ id }',
args: originalObject => ({ id: originalObject.id })
}
}
}
],
mergeTypes: true // << default in v7
})That's it! Under the subschema config merge option, each merged type provides a query for accessing its respective partial type (services without an expression of the type may omit this). The query settings are:
fieldNamespecifies a root field used to request the local type.selectionSetspecifies one or more key fields required from other services to perform this query. Query planning will automatically resolve these fields from other subschemas in dependency order.argsformats the initial object representation into query arguments.
See related handbook example for a working demonstration of this setup. This JavaScript-based syntax may also be written directly into schema-type definitions using the @merge directive of the stitching SDL:
type User {
id: ID!
email: String!
}
type Query {
userById(id: ID!): User @merge(keyField: "id")
}Regardless of how this merge configuration is written, it allows type merging to smartly resolve a complete User, regardless of which service provides the initial representation of it. We now have a combined User type in the gateway schema:
type User {
id: ID!
email: String!
posts: [Post]!
}Types without a Database
It's logical to assume that each postUserById query has a backing database table used to look up the requested user ID. However, this is frequently not the case. Here's a simple example that demonstrates how User.posts can be resolved without the posts service having any formal database concept of a User:
import { makeExecutableSchema } from '@graphql-tools/schema'
const postsData = [
{ id: '1', message: 'Hello', authorId: '7' },
{ id: '2', message: 'Goodbye', authorId: '5' }
]
const postsSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
type Post {
id: ID!
message: String!
author: User!
}
type User {
id: ID!
posts: [Post]!
}
type Query {
postById(id: ID!): Post
postUserById(id: ID!): User
}
`,
resolvers: {
Query: {
postById: (root, { id }) => postsData.find(post => post.id === id),
postUserById: (root, { id }) => ({ id })
},
User: {
posts(user) {
return postsData.filter(post => post.authorId === user.id)
}
}
}
})In this example, the postUserById resolver simply converts a submitted user ID into a stub record that gets resolved as the local User type.
Null Records
The above example will always resolve a stubbed User record for any requested ID. For example, requesting ID 7 (which has no associated posts) would return:
{ "id": "7", "posts": [] }This fabricated record fulfills the not-null requirement of the posts:[Post]! field. However, it also makes the posts service awkwardly responsible for data it knows only by omission. A cleaner solution may be to loosen schema nullability down to posts:[Post], and then return null for unknown user IDs without associated posts. Null is a valid mergable object as long as the unique fields it fulfills are nullable. See the related handbook example for a detailed explanation.
Merging Flow
To better understand the flow of merged object calls, let's break down the basic example above:
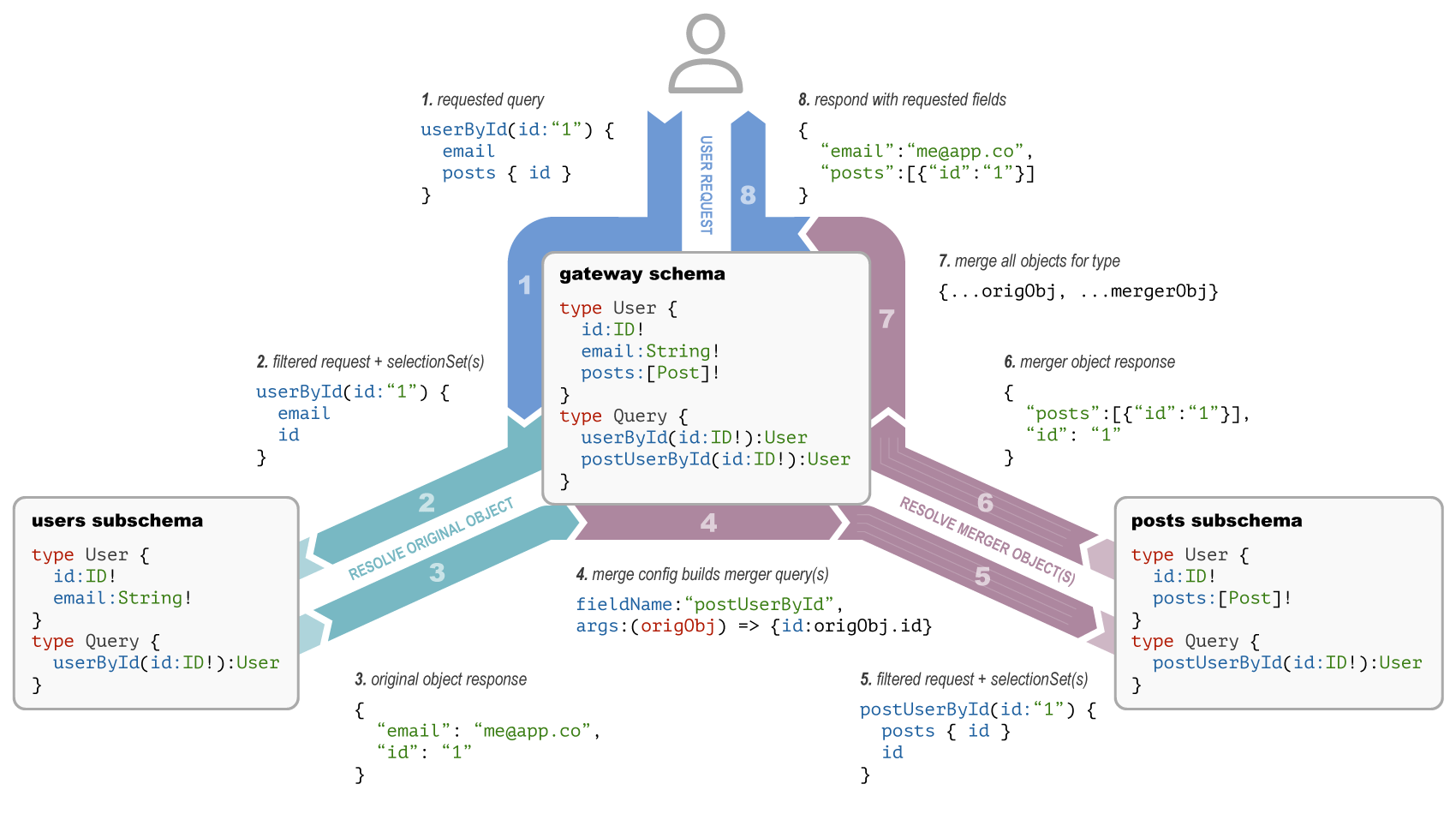
- A request is submitted to the gateway schema that selects fields from multiple subschemas.
- The gateway fetches the resource that was explicitly requested (
userById), known as the original object. This subquery is filtered to match its subschema and adds theselectionSetof other subschemas that must implicitly provide data for the request. - The original object returns with fields requested by the user and those necessary to query other subschemas, per their
selectionSet. - Merge config builds subsequent queries for merger objects that will provide missing data. These subqueries are built using
fieldNamewith arguments derived from the original object. - Subqueries for merger objects are initiated; again filtering each query to match its intended subschema, and adding the
selectionSetof other subschemas†. Merger queries run in parallel when possible. - Merger objects are returned with additional fields requested by the user and those necessary to query other subschemas, per their
selectionSet†. - Merger objects are applied to the original object, building an aggregate result.
- The gateway responds with the original query selection applied to the aggregate merge result.
† Note: merger subqueries may still collect unique selectionSet fields. Given subschemas A, B, and C, it's perfectly valid for schema C to specify fields from both A and B in its selection set. When this happens, resolving C will simply be deferred until the merger of A and B can be provided as its original object.
Batching
The basic example above queries for a single record each time it performs a merge, which is suboptimal when merging arrays of objects. Instead, we should batch many record requests together using array queries that may fetch many partials at once, the schema for which would be:
postUsersByIds(ids: [ID!]!): [User]!
usersByIds(ids: [ID!]!): [User]!Once a service provides an array query for a merged type, batching may be enabled by adding a key method that picks a key from each partial record. The argsFromKeys method then transforms the list of picked keys into query arguments:
import { stitchSchemas } from '@graphql-tools/stitch'
const gatewaySchema = stitchSchemas({
subschemas: [
{
schema: postsSchema,
merge: {
User: {
fieldName: 'postUsersByIds',
selectionSet: '{ id }',
key: ({ id }) => id,
argsFromKeys: ids => ({ ids })
}
}
},
{
schema: usersSchema,
merge: {
User: {
fieldName: 'usersByIds',
selectionSet: '{ id }',
key: ({ id }) => id,
argsFromKeys: ids => ({ ids })
}
}
}
]
})A valuesFromResults method may also be provided to map the raw query result into the batched set. With this array optimization in place, we'll now only perform one query per merged field (versus per record). However, requesting multiple merged fields will still perform a query each. To optimize this further, we can enable query batching:
{
schema: postsSchema,
batch: true,
batchingOptions: {
// ...
},
merge: {
User: {
fieldName: 'postUsersByIds',
selectionSet: '{ id }',
key: ({ id }) => id,
argsFromKeys: ids => ({ ids })
}
}
}Query batching will collect all queries made during an execution cycle and combine them into a single GraphQL operation to send to the subschema. This consolidates networking with remote services and improves database batching within the underlying service implementation. You may customize query batching behavior with batchingOptions—this is particularly useful for providing DataLoader options (opens in a new tab):
batchingOptions?: {
dataLoaderOptions?: DataLoader.Options<K, V, C>;
extensionsReducer?: (mergedExtensions: Record<string, any>, request: Request) => Record<string, any>;
}Using both array batching and query batching together is recommended and should flatten transactional costs down to one query per subservice per generation of data. See related handbook example for a working demonstration of this process.
Unidirectional Merges
Type merging allows services to provide the bare minimum of fields they possess data for—and this is frequently nothing but an ID. For example:
import { makeExecutableSchema } from '@graphql-tools/schema'
let postsSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
type Post {
id: ID!
message: String!
author: User!
}
# ID-only stub...
type User {
id: ID!
}
type Query {
postById(id: ID!): Post
}
`
})
let usersSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
type User {
id: ID!
email: String!
}
type Query {
usersByIds(ids: [ID!]!): [User]!
}
`
})When a stub type like the one above includes no unique fields beyond a key shared across services, then the type may be considered unidirectional to the service—that is, the service holds no unique data that would require an inbound request to fetch it. In these cases, merge config may be omitted entirely for the stub type:
const gatewaySchema = stitchSchemas({
subschemas: [
{ schema: postsSchema },
{
schema: usersSchema,
merge: {
User: {
selectionSet: '{ id }',
fieldName: 'usersByIds',
key: ({ id }) => id,
argsFromKeys: ids => ({ ids })
}
}
}
]
})Stubbed types are quick and easy to setup and effectively work as automatic schema extensions (in fact, you might not need extensions). A stubbed type may always be expanded with additional service-specific fields (see the basic example). However, it requires a query in merge config as soon as it offers unique data.
Merged Interfaces
Type merging will automatically consolidate interfaces of the same name across subschemas, allowing each subschema to contribute fields. This is extremely useful when the complete interface of fields is not available in all subschemas— each subschema simply provides the minimum set of fields that it contains:
const postsSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
interface HomepageSlot {
id: ID!
title: String!
url: URL!
}
type Post implements HomepageSlot {
id: ID!
title: String!
url: URL!
}
`
})
const layoutsSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
interface HomepageSlot {
id: ID!
}
type Post implements HomepageSlot {
id: ID!
}
type Section implements HomepageSlot {
id: ID!
title: String!
url: URL!
posts: [Post!]!
}
type Homepage {
slots: [HomepageSlot]!
}
`
})In the above, both Post and Section will have a common interface of { id title url } in the gateway schema. The difference in interface fields between the gateway schema and the layouts subschema will automatically be expanded into typed fragments for compatibility. See related handbook example for a working demonstration.
Multiple Keys
Merged types may define multiple key fields across services that join through a central service, for example:
- Catalog service:
type Product { upc } - Vendors service:
type Product { upc id } - Reviews service:
type Product { id }
Given this graph, the Vendors service must provide lookups for its Product type by either upc or id to enable all possible traversals. These multiple pathways can be configured as entryPoints:
import { stitchSchemas } from '@graphql-tools/stitch'
const gatewaySchema = stitchSchemas({
subschemas: [
{
schema: catalogSchema,
merge: {
Product: {
selectionSet: '{ upc }',
fieldName: 'productByUpc',
args: upc => ({ upc })
}
}
},
{
schema: vendorsSchema,
merge: {
Product: {
// Entry points for each key format:
entryPoints: [
{
selectionSet: '{ upc }',
fieldName: 'productByUpc',
args: upc => ({ upc })
},
{
selectionSet: '{ id }',
fieldName: 'productById',
args: id => ({ id })
}
]
}
}
},
{
schema: reviewsSchema,
merge: {
Product: {
selectionSet: '{ id }',
fieldName: 'productById',
args: id => ({ id })
}
}
}
]
})Note that the entryPoints option replaces a merged type's base selectionSet and fieldName. This configuration is not currently possible with SDL directives, though it may be statically configured alongside of SDL parsing.
Computed Fields
APIs may leverage the gateway layer to transport field dependencies from one subservice to another while resolving data. This is useful when a field in one subschema requires one or more fields from other subschemas to be resolved, as described in the federation spec (opens in a new tab). For example:
import { makeExecutableSchema } from '@graphql-tools/schema'
import { stitchSchemas } from '@graphql-tools/stitch'
const productsSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
type Product {
id: ID!
price: Float!
weight: Int!
}
type Query {
productsByIds(ids: [ID!]!): [Product]!
}
`,
resolvers: {
// ...
}
})
const storefrontsSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
directive @computed(selectionSet: String!) on FIELD_DEFINITION
type Storefront {
id: ID!
availableProducts: [Product]!
}
type Product {
id: ID!
shippingEstimate: Float! @computed(selectionSet: "{ price weight }")
deliveryService: String! @computed(selectionSet: "{ weight }")
}
input ProductInput {
id: ID!
price: Float
weight: Int
}
type Query {
storefront(id: ID!): Storefront
_products(representations: [ProductInput!]!): [Product]!
}
`,
resolvers: {
Query: {
storefront: (root, { id }) => ({ id, availableProducts: [{ id: '23' }] }),
_products: (root, { representations }) => representations
},
Product: {
shippingEstimate: rep => (rep.price > 50 ? 0 : rep.weight / 2),
deliveryService: rep => (rep.weight > 50 ? 'FREIGHT' : 'POSTAL')
}
}
})
const gatewaySchema = stitchSchemas({
subschemas: [
{
schema: productsSchema,
merge: {
Product: {
selectionSet: '{ id }',
fieldName: 'productsByIds',
key: ({ id }) => id,
args: ids => ({ ids })
}
}
},
{
schema: storefrontsSchema,
merge: {
Product: {
selectionSet: '{ id }',
fieldName: '_products',
key: ({ id, price, weight }) => ({ id, price, weight }),
argsFromKeys: representations => ({ representations })
}
}
}
]
})In the above, the shippingEstimate and deliveryService fields are marked with @computed directives (see stitching directives SDL), which specify additional field-level dependencies required to resolve these specific fields beyond the Product type's base selection set. When a computed field appears in a query, the gateway will collect that field's dependencies from other subschemas, so they may be sent as input with the request for the computed field(s).
The @computed SDL directive is a convenience syntax for static configuration that can be written as:
{
schema: storefrontsSchema,
merge: {
Product: {
selectionSet: '{ id }',
fields: {
shippingEstimate: {
selectionSet: '{ price weight }',
computed: true
},
deliveryService: {
selectionSet: '{ weight }',
computed: true
}
},
fieldName: '_products',
key: ({ id, price, weight }) => ({ id, price, weight }),
argsFromKeys: representations => ({ representations })
}
}
}A field-level selectionSet specifies field dependencies while the computed setting structures the field in a way that assures it is always selected with this data provided. The selectionSet is intentionally generic to support possible future uses.
Implementation note: to assure that computed fields are always requested directly by the gateway with their dependencies provided, computed and non-computed fields of a type in the same subservice are automatically split apart into separate schemas. This means that computed and non-computed fields may require separate resolution steps. You may enable query batching to consolidate requests whenever possible.
The main disadvantage of computed fields is that they cannot be resolved independently from the stitched gateway. Tolerance for this subservice inconsistency is largely dependent on your own service architecture. An imperfect solution is to deprecate all computed fields within a subschema, and then normalize their behavior in the gateway schema with a RemoveObjectFieldDeprecations transform. See related handbook example.
Canonical Definitions
Managing the gateway schema definition of each type and field becomes challenging as the same type names are introduced across subschemas. By default, the final definition of each named GraphQL element found in the stitched subschemas array provides its gateway definition. However, preferred definitions may be marked as canonical to receive this final priority. Canonical definitions provide:
- an element's description (doc string).
- an element's final directive values.
- a field's final nullability, arguments, and deprecation reason.
- a root field's default delegation target.
The following example uses stitching directives to mark preferred subschema elements as @canonical:
"Represents an authenticated user"
type User @canonical {
"The primary key of this user record"
id: ID! @mydir(schema: "users")
"other description"
field: String!
}
type Query {
"Users schema definition"
user(id: ID!): User @canonical
}type Post {
id: ID!
}
"other description"
type User {
"other description"
id: ID! @mydir(schema: "posts")
"The canonical field description"
field: String @canonical
"Posts authored by this user"
posts: [Post!]
}
type Query {
"Posts schema definition"
user(id: ID!): User
}The above ASTs will merge into the following gateway schema definition, and the root user field will proxy the Users subschema by default:
"Represents an authenticated user"
type User {
"The primary key of this user record"
id: ID! @mydir(schema: "users")
"The canonical field description"
field: String
"Posts authored by this user"
posts: [Post!]
}
type Query {
"Users schema definition"
user(id: ID!): User
}- Types marked as canonical will provide their definition and that of all of their fields to the combined gateway schema.
- Fields marked as canonical will override those of a canonical type.
- Root fields marked as canonical will specify which subschema the field proxies by default for new queries entering the graph.
Only one of any given type or field may be made canonical. Fields that are unique to one service (such as User.posts above) have no competing definition so are canonical by default.
The above SDL directives can also be written as static configuration:
import { stitchSchemas } from '@graphql-tools/stitch'
const gatewaySchema = stitchSchemas({
subschemas: [
{
schema: usersSchema,
merge: {
User: {
// ...
canonical: true
},
Query: {
fields: {
user: { canonical: true }
}
}
}
},
{
schema: postsSchema,
merge: {
User: {
// ...
fields: {
email: { canonical: true }
}
}
}
}
]
})Implementation note: canonical settings are only used for building the combined gateway schema definition and
defaulting root field targets; otherwise, they are given no special priority in runtime query planning (which always
selects necessary fields from as few subschemas as possible). You may override the assembly of canonical definitions
using typeMergingOptions.
Type Resolvers
Similar to how GraphQL objects implement field resolvers, merging implements type resolvers for fetching and merging partial types. These resolvers are configured automatically, though advanced use cases may want to customize some or all of their default behavior. Merged type resolver methods are of type MergedTypeResolver:
export type MergedTypeResolver = (
originalObject: any, // initial object being merged onto
context: Record<string, any>, // gateway request context
info: GraphQLResolveInfo, // gateway request info
subschema: SubschemaConfig, // target subschema configuration
selectionSet: SelectionSetNode, // target subschema selection
key?: any // the batch key being requested
) => anyWrapped Resolvers
Frequently we want to augment type resolution without fundamentally changing its behavior. This can be done by building a default resolver function, and then wrapping it in a custom implementation. For example, adding statsd instrumentation (opens in a new tab) might look like this:
import { createMergedTypeResolver, stitchSchemas } from '@graphql-tools/stitch'
import { SDC } from 'statsd-client'
const statsd = new SDC({
/* ... */
})
function createInstrumentedMergedTypeResolver(resolverOptions) {
const defaultResolve = createMergedTypeResolver(resolverOptions)
return async (obj, ctx, info, cfg, sel, key) => {
const startTime = process.hrtime()
try {
return await defaultResolve(obj, ctx, info, cfg, sel, key)
} finally {
statsd.timing(info.path.join('.'), process.hrtime(startTime))
}
}
}
const schema = stitchSchemas({
subschemas: [
{
schema: widgetsSchema,
merge: {
Widget: {
selectionSet: '{ id }',
key: ({ id }) => id,
resolve: createInstrumentedMergedTypeResolver({
fieldName: 'widgets',
argsFromKeys: ids => ({ ids })
})
}
}
}
]
})The createMergedTypeResolver helper accepts a subset of options that would otherwise be included directly on merged type configuration: fieldName, args, argsFromKeys, and valuesFromResults. A default MergedTypeResolver function is returned and may be wrapped with additional behavior and then assigned as a custom resolve option for the type.
Custom Resolvers
Alternatively, you may provide completely custom resolver implementations for fetching types in non-standard ways. For example, fetching a merged type from a REST API might look like this:
{
schema: widgetsSchema,
merge: {
Widget: {
selectionSet: '{ id }',
async resolve(originalObject) {
const mergeObject = await fetchViaREST(originalObject.id)
return { ...originalObject, ...mergeObject }
}
}
}
}When incorporating plain objects, always extend the provided originalObject to retain the internal merge configuration. You may also return direct calls to delegateToSchema and batchDelegateToSchema (as described for schema extensions), however—always provide these delegation methods with a skipTypeMerging: true option to prevent infinite recursion.